I got tired of Claude's misaligned ASCII diagrams. So I built claude-canvas.
Why LLMs can't draw, and how to give Claude a real canvas.
"Any project with Claude's signature misaligned ASCII diagram just screams DON'T..." — HN, April 2026
Misaligned box-drawing has become the tell. Pipes that don't line up, labels overflowing boxes — when I see that in a README I assume the rest is sloppy too.
I've been hitting this wall for months. Last week I shipped something for it.
Repo: github.com/notpritam/claude-canvas
The problem isn't prompting
LLMs are sequential token predictors. They have no 2D coordinate space in their head — they reason about layout verbally, which falls apart past ~5 elements. That's structural, not a prompt issue.
"An 8 year old child could do this without all the faff... life is too short to get you to correct it." — GitHub issue #16473, after 10+ iterations trying to align ASCII
By 2026 there are validators, repair-loop libraries, and at least six Claude Code skills built around this one gap. The quantity of workarounds is the measure of the pain.
The fix isn't a smarter model. It's handing spatial reasoning off to a tool — and giving the model a feedback loop so it can see what it drew.
Why the existing options don't close the loop
Mermaid renders in GitHub and Obsidian, and LLMs have seen tons of it. But push past trivial and you're inserting <br> everywhere to keep labels from wrapping, and Claude Code's terminal has no renderer at all — you copy/paste into mermaid.live to see anything.
Excalidraw / draw.io / tldraw MCPs are closer. Real canvas, real interaction. But as the Nimbalyst survey put it, "almost none give an AI coding agent direct access to the live file." The agent draws once and never sees the result.
Claude's HTML viz and ChatGPT Canvas make things pretty, but they're general-purpose. They don't know what an architecture diagram is.
Every path ends the same way: you open Excalidraw and draw it yourself.
What claude-canvas does
A Claude Code skill that closes the loop. You type /visualize how OAuth2 device flow works. Within two seconds:
Claude reads a 400-line
SKILL.mdof visualization rules.It generates typed-node JSON and writes it to disk.
A local Node server spins up on a random port.
Your browser opens to a tldraw canvas with the diagram.
You drag nodes, edit labels, reattach arrows — every change auto-saves. When you ask Claude to add or change something, it reads your current state, updates the JSON, and your tab hot-swaps via SSE. Your layout stays.
The canvas is GPU-rendered (tldraw on HTML5 Canvas), so 20+ nodes drag at 60fps.
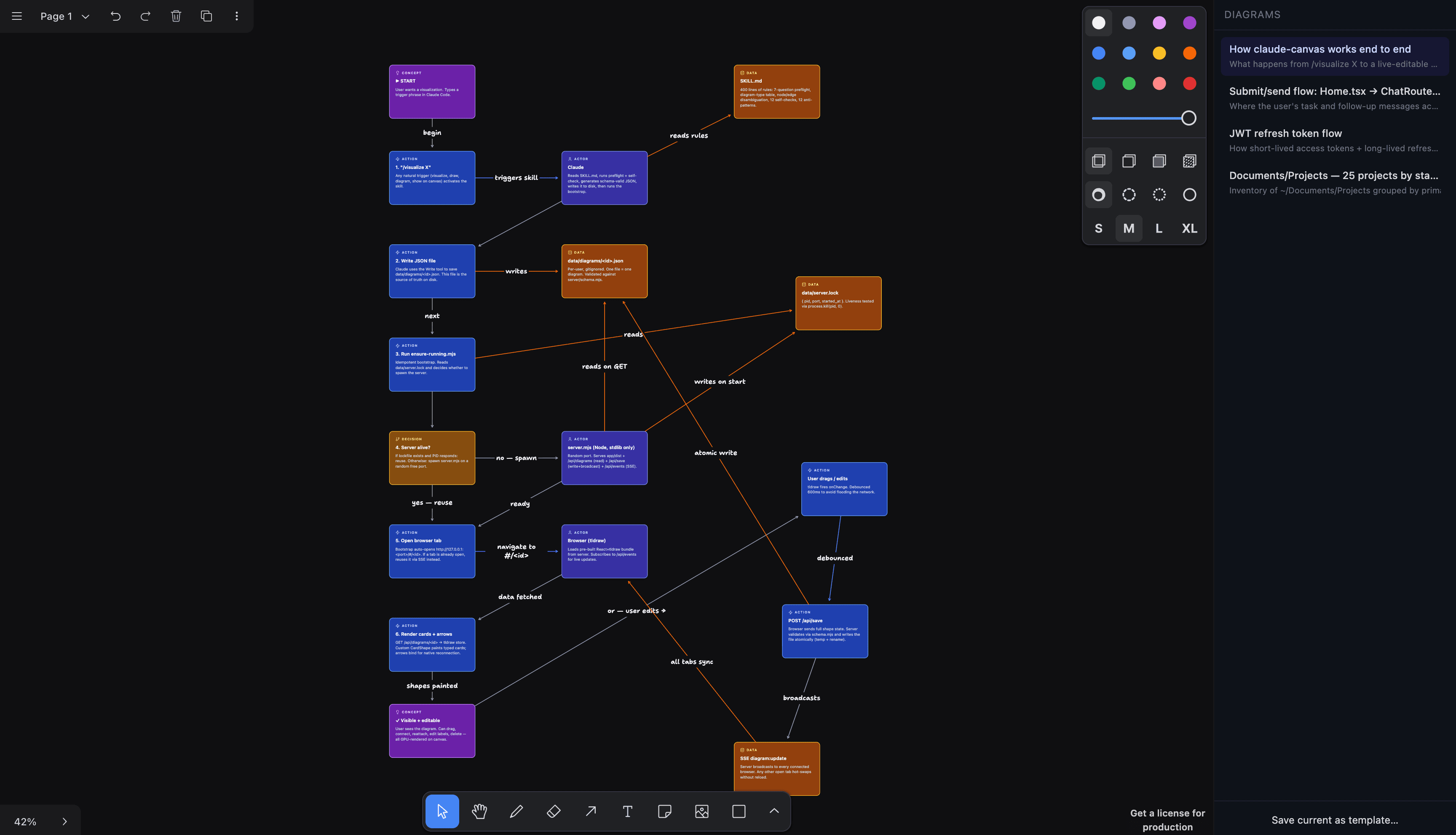
Architecture

Two flows. Generation: invoke → JSON → server up → canvas opens. Live-edit: drag → POST /api/save → SSE broadcast → tabs hot-swap.
One Node file, stdlib only, no runtime deps. Browser bundle pre-built and committed, so there's no npm install on the consumer side. Random port, lockfile, atomic writes, 30-minute idle exit.
The visualization rules
Standing up tldraw was easy. The hard part: a model left alone produces diagrams that render but don't communicate. Identical rectangles, generic labels, mixed abstraction levels.
SKILL.md leans on Tufte's data-ink principle, the C4 model, Sweller's cognitive load theory, Wurman's LATCH, and Mermaid community conventions. It boils down to:
A 7-question preflight before any JSON — audience, abstraction level, intent type, entry/exit, branches.
A diagram-type → structure table mapping 8 user-intent patterns to node/edge choices.
Hard limits: ≤15 nodes, ≤4 edges per node, label ≤4 words, edge label ≤5 words verb-first.
A 12-item self-check before invoking the canvas.
12 auto-fail anti-patterns: spaghetti edges, mixed abstraction, god nodes, cramped spacing.
The quality bar is in the instructions, not in the model's discretion.
Try it
mkdir -p ~/.claude/skills
git clone --branch v0.2.0 https://github.com/notpritam/claude-canvas.git ~/.claude/skills/claude-canvas
That's the whole install. Node 20+ is the only requirement.
Then in Claude Code:
/visualize how DNS resolution works/visualize our signup flow"draw out why deploys cause downtime"
MIT-licensed (with a small "Made with tldraw" attribution per their license).
Help wanted on: more default templates, bundle size (tldraw ships Mermaid integration we don't use), server-side file watching, better swimlanes.
The point
LLMs are not going to learn spatial reasoning natively. Better prompting and bigger models won't fix it.
What fixes it: a canvas, a schema, a feedback loop, and rules grounded in real visualization research. That's the gap this fills.
github.com/notpritam/claude-canvas — star to follow along. v0.3 next: custom node types, code-level diagrams, PNG export.